


Table des matières
Toute IA a une limite de choses que tu peux lui dire dans une même conversation. Prenons un cas typique en vibecode :
Tu lui expliques ton architecture. Elle consulte ta code base, puis code. Tu corriges. Elle re-code. Au bout d'un moment, elle s'arrête, plus de contexte... elle te demande de "compacter". C'est ce que tu fais, mais quelques messages plus tard, tu vois qu'elle crée une table qui pourtant existe déjà... L'IA a oublié l'architecture de ton projet.
Ce n'est pas un bug. C'est la fenêtre de contexte.
C'est quoi un token ?
Pour comprendre pourquoi l'IA oublie, il faut comprendre comment elle "lit" tes messages.
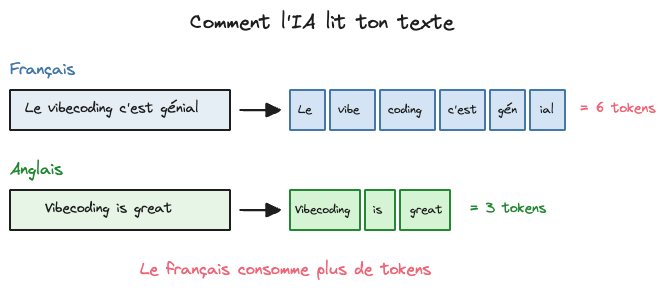
L'IA ne lit pas des mots, elle lit des tokens. Un token, c'est un mot que l'IA retrouve régulièrement dans sa base de données. Elle va analyser tout le texte que tu lui envoies en se basant sur les mots qu'elle connaît le plus, donc ceux qui sont le plus fréquents dans ses bases de données.
Donc si un mot est peu fréquent ou n'existe pas dans sa base de données, elle va l'analyser avec d'autres mots qui le composent. Par exemple iCloud fera deux tokens : "i" et "cloud" qui sont deux mots très fréquents. Le mot comptera donc pour 2 tokens alors qu'on a un seul mot.
NB : Tu peux t'amuser à tester ici
Comme les IA sont majoritairement entraînées sur des bases de données anglaises, elles auront beaucoup plus de mal à reconnaître des mots français. Elles consomment donc beaucoup plus de tokens pour les textes en français. C'est pour ça qu'on va utiliser plus de tokens quand on parle en français à l'IA (donc que ça coûte plus cher). Et l'IA comprend beaucoup mieux quand on lui parle en anglais parce qu'elle reconnaît directement les mots et les concepts, elle n'a pas besoin de les deviner.
La fenêtre de contexte : l'analogie du bureau
Ok, donc l'IA compte en tokens et pas en mots, et elle compte les tokens qu'elle produit et ceux qu'elle reçoit. Mais pour que l'IA fasse sens de tous ces tokens, il faut qu'elle arrive à les replacer dans un contexte. Par exemple le mot "feed" peut avoir plusieurs significations selon le contexte. Les réseaux sociaux ? Ou nourrir au sens littéral ?
Bref, il faut que l'IA puisse recontextualiser et comprendre de quoi on parle, quel est notre problème, et faire le tri dans les informations qu'elle reçoit ou qu'elle va aller chercher. Il y a des grands modèles particulièrement performants parce qu'ils accèdent à une grande base de données pour aller chercher des réponses à nos questions. Mais quoi qu'il arrive, le contexte de notre conversation reste limité, car s'il devient trop grand, ça devient compliqué pour l'IA de garder le contexte concis et de comprendre vraiment de quoi on parle. Elle est obligée de limiter toutes les informations qu'on lui donne, sinon elle n'arrive plus à retrouver le contexte des concepts qu'on aborde avec elle.
Cette limite de taille de contexte, c'est ce qu'on appelle la fenêtre de contexte. Cette fenêtre de contexte est limitée et dépend du modèle du LLM. Pour Claude, elle est de 200 000 tokens (ce qui est relativement confortable). Mais dans des gros projets de code, ça se remplit extrêmement vite à mesure qu'on donne des fichiers entiers à lire à l'IA qui font parfois plusieurs centaines de lignes.
Et les fichiers et nos messages de conversation ne sont pas la seule chose qui remplit cette fenêtre de contexte. Les outils que l'IA a à disposition (MCP, agents, commandes) consomment aussi de la place. Car le simple fait qu'ils existent et que l'IA doit être consciente qu'elle peut les utiliser lui prend de la place.
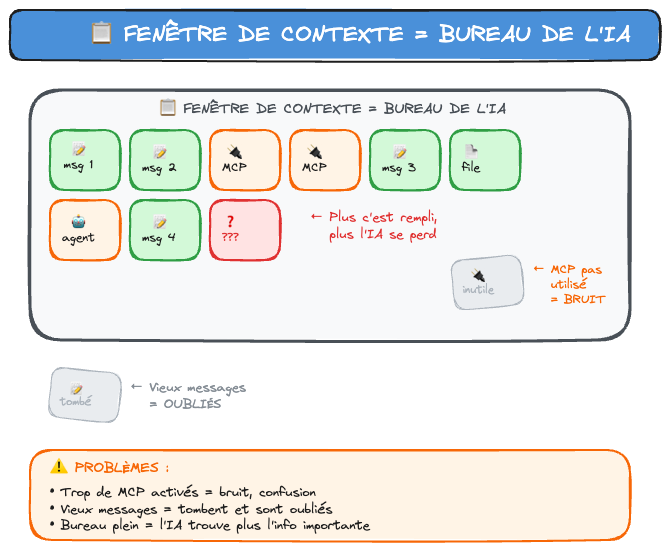
Pour mieux comprendre, imagine un bureau avec une pile de feuilles.
Chaque message que tu envoies, chaque réponse de l'IA, chaque fichier qu'elle lit — tout ça s'empile sur le bureau.
Le problème ? Le bureau a une taille fixe.
- Claude : ~200 000 tokens (environ 150 000 mots)
- ChatGPT : ~128 000 tokens
- Gemini : jusqu'à 2 millions de tokens
Quand la pile déborde, les feuilles du bas tombent. L'IA oublie le début de la conversation.
C'est pour ça qu'elle te redemande des infos que tu lui as déjà données. Elle ne les a plus.
Les symptômes de saturation
Comment savoir que l'IA sature ?
En effet, plus on va donner d'informations à l'IA, plus elle risque d'halluciner, c'est-à-dire d'inventer des choses. Et ça peut arriver même avant qu'on atteigne la limite de la fenêtre de contexte.
Voici les signes :
1. Elle hallucine
Elle invente des fonctions qui n'existent pas, des variables que tu n'as jamais créées, des fichiers imaginaires.
2. Elle se répète
Elle propose des solutions qu'elle a déjà proposées (et que tu as déjà rejetées).
3. Elle oublie les instructions
Tu lui as dit "utilise TypeScript strict", et elle te sort du JavaScript avec des any partout.
Quand tu vois ces signes, c'est que le bureau déborde.
Comment éviter la saturation
1. Une tâche = une conversation
Ne fais pas tout dans le même chat. Nouvelle feature ? Nouveau chat. Bug à fixer ? Nouveau chat.
2. Résume, ne copie pas tout
Au lieu de coller 500 lignes de code, résume : "J'ai un composant [...] qui fait x..."
3. Utilise la documentation intelligemment
Ne charge pas tout ton projet d'un coup. Donne à l'IA ce dont elle a besoin pour la tâche en cours. Et donc, ça passe par donner une partie de documentation à IA pour la feature concernée.
4. Fais des points de sauvegarde
Quand tu atteins un état stable, documente-le. Si l'IA oublie, tu peux la remettre à niveau rapidement. Dans des gros projets, tu peux automatiser cette documentation en ayant un workflow de documentation.
Et c'est ce que j'utilise, moi avec mon système de Memory Bank. C'est un système de documentation structurée qui permet à l'IA de retrouver le contexte sans tout recharger :
context.md: ce sur quoi tu travailles maintenantstructure.md: comment ton projet est organisétech-stack.md: ta stack, tes conventions
L'IA lit ces fichiers au début de chaque session et retrouve le contexte sans avoir besoin de lire tous les fichiers du projet.
Je le détaillerai dans de futurs articles
5 - Désactive les outils inutiles
Ton IA peut utiliser différents outils pour avoir de la documentation ou pour avoir plus de capacité, mais tous ne sont pas utiles pour chaque feature que tu codes. Désactive ces outils si tu n'en as pas l'utilité dans cette feature, ça permettra à ton IA d'être plus pertinente et tu pourras parler avec elle plus longtemps.
Pourquoi c'est crucial pour les gros projets
Sur un petit script, la saturation n'arrive jamais. Tout tient dans la fenêtre.
Mais dès que ton projet grossit — plusieurs fichiers, plusieurs features, de l'historique — tu tapes la limite.
C'est là que la différence se fait entre ceux qui galèrent ("l'IA comprend rien à mon projet") et ceux qui avancent vite (ils ont structuré leur contexte).
Le contexte, c'est la clé
La puissance de l'IA n'est pas dans le modèle (un peu quand même). C'est dans le contexte que tu lui donnes.
Un modèle moyen avec un excellent contexte bat un modèle puissant avec un contexte pourri.
Comprendre les tokens et la fenêtre de contexte, c'est la première étape pour devenir un bon vibecoder. Et une fois que tu le maîtriseras, tu pourras utiliser n'importe quelle IA, la plus puissante sur le marché, pour aller plus vite et plus loin. Tu éviteras ainsi beaucoup d'angoisse à parler des heures à l'IA pour lui faire corriger ses bêtises.
Maintenant tu sais pourquoi l'IA oublie et comment l'éviter.
Dans le prochain article, on parle des outils : quel IDE choisir selon ton profil et ton projet.
Commentaires